A14:指令并行度的极限?
苹果在前阵子带来了A14和M1。其中可以说非常重点的可以来聊一下他们的大核心,Firestorm核心的架构。
频率以内的性能
首先在了解Firestorm架构之前,可以先来了解一下Firestorm的绝对性能和每时钟性能PPC的提升:
| GB5 单核 | A14 偷跑 | A13 | 性能比例 | iPhone 12 | A14性能比例 | MBP M1 | M1 性能比例 |
| 加密 | 2475 | 1925 | 128.5714% | 2600 | 135.0649% | 2732 | 141.9221% |
| 整数 | 1432 | 1232 | 116.2338% | 1454 | 118.0195% | 1570 | 127.4351% |
| 浮点 | 1760 | 1462 | 120.3830% | 1753 | 119.9042% | 1865 | 127.5650% |
| GB5 单核 PPC | A14 偷跑 | A13 | PPC 比例 | iPhone 12 | A14性能比例 | MBP M1 | M1 性能比例 |
| 加密 | 827.7591973 | 723.6842105 | 114.3813% | 869.5652174 | 120.1581% | 853.75 | 117.9727% |
| 整数 | 478.9297659 | 463.1578947 | 103.4053% | 486.2876254 | 104.9939% | 490.625 | 105.9304% |
| 浮点 | 588.6287625 | 549.6240602 | 107.0966% | 586.2876254 | 106.6707% | 582.8125 | 106.0384% |
可以看到,其中提升最明显的事加密性能,除此之外,浮点和整数性能提升并不明显。尤其是整数性能,仅仅提升了大约5%的PPC。
当然需要注意的是A14运行在3GHz和LPDDR4X内存,而且M1运行在M1和更大延迟更低的内存。他们降频到A13的频率上,内存延迟造成的性能损失水平会更低,PPC会提升更明显。实际上如果我知道M1的内存延迟水平,我就可以推算出在2.66GHz下的PPC水平。
虽然,之前的版本是估算了25%的memory bound。但是在群友有iphone12的基础之下,我终于可以去计算,A14真正的在不同频率下的表现:
| A14正常 | A14省电 | |
| 频率(GHz) | 2.99 | 1.29 |
| 整数 | 1444 | 635 |
| 浮点 | 1763 | 772 |
| 加密 | 2601 | 1127 |
| GB4 内存延迟 | 100ns | 209.8ns |
| GB4 内存带宽 | 28.6GB/s | 27.7GB/s |
| A14正常 | A14省电 | PPC提升 | |
| PPC 整数 | 482.9431438 | 492.248062 | 1.93% |
| PPC 浮点 | 589.632107 | 598.4496124 | 1.50% |
| PPC 加密 | 869.8996656 | 873.6434109 | 0.43% |
可以看到,A14省电模式并没有明显的PPC提升。这是因为在省电模式下,内存延迟翻了倍,这会使得实际A14在运行的时候memory bound有非常夸张的增加。但是,GB4正好有内存测试,可以给我提供足够的数据,去还原出原始的(内存延迟正常下的性能表现)
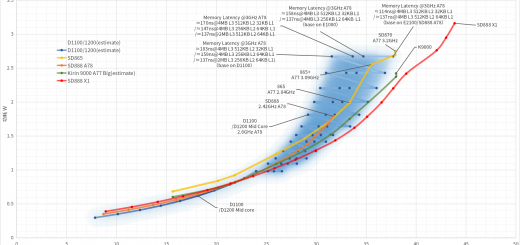
经过计算,可以知道,A14的GB5 memory bound在整数16.69%,浮点13.62%,加密4.34%。
同时,也可以计算出M1的等效的memory bound缩小幅度(来自于内存延迟和内存带宽翻倍)在94.64左右。这等于说类似于一个95ns的内存延迟的水平
然后我们就可以计算出Firestorm的A14和M1在2.66GHz,也就是A13的频率上的大致的PPC水平:
| GB5 PPC 2.66GHz | A13 | A14 | M1 |
| 整数PPC 估值 | 463.1578947 | 497.190917 | 507.2659983 |
| PPC性能比例 | 100.00% | 107.35% | 109.52% |
| PPC 提升 | 0.00% | 7.35% | 9.52% |
这7-10%的整数PPC提升,一定是有相应的改进的,这点提升毕竟说大不大但是说小也不小。
架构:更强的内存子系统……

苹果在Firestorm依旧拥有8解码宽度。
最明显的是Firestorm拥有了4*128bit宽的浮点/SIMD管线,这意味着Firestorm拥有和X86主流的Skylake和Zen2/3相同的SIMD宽度。当然,这两者之间的指令差距,意味着苹果虽然拥有了4*128bit的SIMD,但是并不意味着会拥有完全一致的性能水平。而且M1也只是运行在3.2GHz。
但是话又要说回来,对于SIMD吞吐这类的需求,还有相当一部分瓶颈来自于内存带宽。受限于内存带宽,他们之间的当然也不会有频率上的差距那么大。
整数的部分,执行器并没有什么变化。实际上,你应该可以考虑8宽的解码宽度将会在PPC几乎没有增益。
这也是我希望在这里强调的第一个问题,即使是ARM端可以说天生对指令吞吐要求更高。但是更加深层是,几乎绝大部分传统的CPU需求中,程序逻辑和计算是没有办法并行化的。这种原理性上并行化不可能,不仅仅是体现在,绝大部分程序依旧依赖单核性能。更加也是体现在,在CPU内部,每个指令的并行度也是不高的。这使得随着CPU微架构变得越来越宽,增加宽度的收益会变得越小。甚至根本没有收益,反过来以功耗作为代价。

显然这就是今天苹果面临的情况,事实上你可以说是所有传统CPU性能需求下大家都面临的问题。所以现在CPU的多线程和SIMD吞吐的方向,都只是向高并行度的HPC的转移,尽管这种计算需求和99%的实际需求都差了十万八千里。
所以Firestorm真正的改进在于内存子系统和缓冲等。
内存子系统,其中的内存损失/指令缓存未命中/TLB,构成了如今CPU的资源浪费的绝大部分。实际上在传统的CPU需求在,诸如网页浏览,其资源浪费达到了大约50.7%,而实际执行的资源只有18.2%

苹果在Firestorm上,最明显的第一个改动就是一级指令缓存增加到192KiB,一级数据缓存增加到128KiB,同时延迟仅仅有3周期。A14的L2大小在6MB,M1在12MB。除此之外,ROB从560增加到630,而同代X1仅仅有224条指令。
重命名寄存器/浮点重命名寄存器有354/384条(当然,实际会更多,有一部分寄存器是这里不会被发现的)是zen3的接近3倍。Load和store队列在148/106,也是在业界超大的水平了。一级TLB从128页增加到256页,翻了倍,覆盖16KiB*256=4MiB,而二级TLB覆盖了3072*16KiB=48MiB。
如此大的内存子系统,才是Firestorm达到了这样的PPC提升的基础。可以说,苹果已经将整数端的指令宽度挖掘的差不多了,接下来苹果的一个改进方向是拓宽SIMD管线,同时当然也要跟随的拓宽解码预取,需要更大的寄存器更大的缓冲,更大的内存带宽。另外一方面,传统的CPU性能需求,就只剩下堆寄存器TLB缓冲,以及增加缓存。
当然,缓存这东西,越大他的延迟就越高,这也是为什么苹果这方面的积累很强。一级缓存的延迟周期实际上比X86平台的zen3/sunnycove更低,同时拥有zen3的4倍以上的大小。
当然,这里面也有一部分是实际上苹果的运行频率更低的原因。这也就是说,如果苹果硬需要M1跑高频,实际上寄存器就可能会太大而延迟跟不上频率,缓存的延迟周期也会增加。最终CPU资源造成大量浪费。实际上你可以预期如果M1最终能运行上5.4GHz,仅仅内存子系统的延迟就会造成PPC降低到大约M1现在的89%的水平,在这基础上实际寄存器缓冲区队列等等会受限于时延做不大规模,所以在这基础上还会有更大的性能损失。
而且实际处理器流水线本身就是目的缩短每一阶段的时延,提高频率。跑高频率确实需要更长的流水线,作为代价,清空流水线的损失也越大。实际在5.4GHz上,估计PPC会降低到78-75%的水平,甚至考虑流水线长度会降低到几乎71%的水平。
这使得M1如果真要给高频做优化,比如保持Firestorm的CPU宽度硬跑上5.4GHz,也未必还能有20%的性能提升。(我这里参考的是Skylake,但是像Firestorm这么大缓存的系统,对缓存性能依赖更大,因为时延的原因,最终的影响更大,而且还有隐性的寄存器规模不得不因为时延削减,使得在core bound等形式上的浪费也会更大。实际上这么考虑在224%的DRAM bound,甚至取决于具体负载对内存的依赖度更大到最高360%DRAM bound都是可能的)
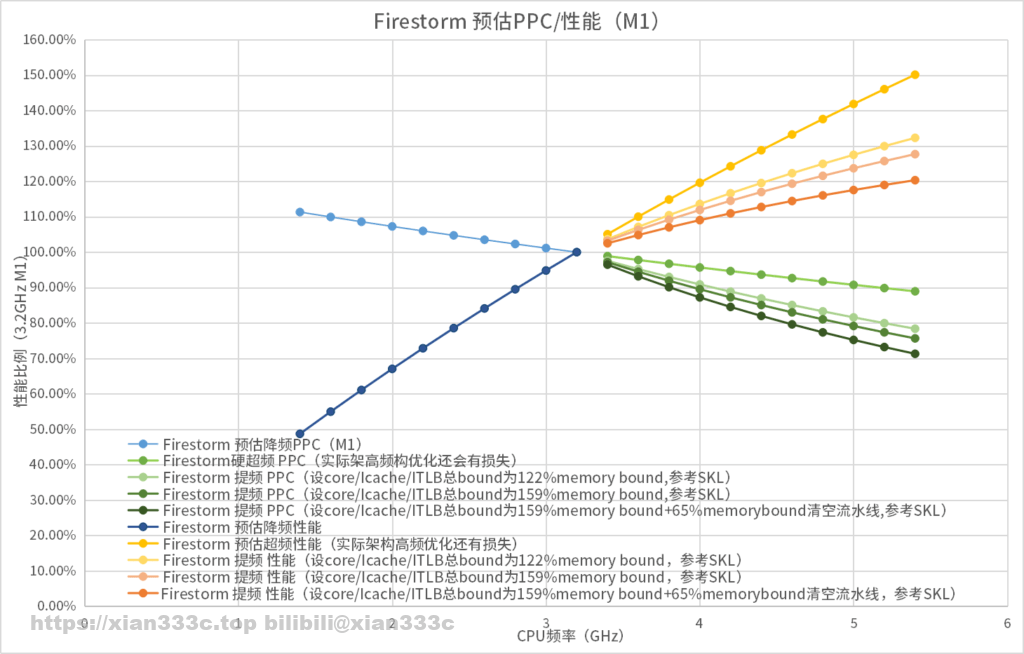
这其实也是要说,单拿CPU的PPC说他多厉害也并不合理。就现在来看,Firestorm的绝对性能可以达到Zen3和Willow Cove低电压的水平,这就是他的实际表现。当然,可以说还在使用big.LITTLE的苹果,如果真想要继续改善内存系统。他的改进空间实际上要比Zen3的CPU独占L1/2群簇共享L3,以及Tigerlake的独占L1/2共享系统缓存,和DynamiQ的独占L1/2共享L3加上系统缓存,这样的改进空间更大。或者可以说苹果现在的缓存层级数还是属于偏少的,从而显得改进的空间较大。

博主说的透彻。现代cpu面临的困境是很难的提升线性性能但需求为线性的矛盾。这具体体现为通过挖掘传统线性需求中的可并行潜力收益越来越低,也体现为能效比下降。我觉得这是一个需要硬件和软件需要共同去解决的问题。我们的世界本身就是一个局部线性同时全局并行的模型,只是摩尔定律早期大量推动了线性编程模型无成本的性能提升,让我们忽视了这一点。更加适应分布式及并行计算还有异构计算的硬件架构设计、操作系统、语言以及软件架构及实现共同作用,才能更好的解决当前困境。我们正处于亟待转变的一个阵痛期,但这也是充满机会的时代。
过程和结论有明显冲突,因为省电模式内存带宽没有下降,说明内存频率并没有缩水,也就是说内存延迟升高的原因明显是cache的频率下降了,这就带来了额外的问题,A14和M1的延迟是不同的,M1比A14要低一些,那么,M1的频率究竟要到多少才会内存延迟撞墙(频率升高,内存延迟不下降),这是个未知数,如果按照DDR的算法,LPDDR4 2133MHz的上限是4266MHz,当然,这只是理论,LPDDR5就不用说了,3200可以到6400MHz,所以我个人认为你最后的PPC折减图是完全错误的,我甚至认为到4GHz前,PPC都不会折减,当然,5nm HD估计也冲不了4GHz。
或许CPU的整数性能已经不重要了.还是要多看下GPU性能.