kirin990E/820E:屏蔽和良品率
华为推出了带有kirin990E的机器,甚至现在都有Kirin820E的机器。这种把原本芯片屏蔽一部分拿出来卖二的操作当然是很普遍的,A12X事原本8核GPU屏蔽一个核,K9000E事屏蔽两个GPU核。还有比如Tigerlake-U的所有SKU,都是从一个满配置的核心屏蔽出来的,等等等等。
我在这里就算一下,这样屏蔽之后,能从废片里重新拿出来多少用。在这里,7nmEUV并没有什么直接的参数,这里参考了台积电的5nmEUV。实际上台积电EUV光的工艺事直接转到5nm节点的,7nmEUV只生产过Kirin990 5g版本,这也会导致这节点实际上没什么机会控制缺陷密度。这里就估算在0.2defect/cm^2的水平。至于这7nm就用台积电官宣数据来。


在计算良品率的时候,这里都使用了Murphy模型,其实是在统计完之后,才发现这里的情况也都是可以使用seeds模型的。不过考虑还很多良品率计算都直接不管什么条件都套Murphy模型,所以在这里也问题不大。
在这里,计算一下可以发现,K990E相对于K990提升了大约0.32%的良品率。这个幅度当然很小。类似的K820作为985的屏蔽版,提升了0.17%的良品率,K820E相对于820又可以提升0.13%的良品率。这个水平究竟换成多少片会有多少变化呢?假设Kirin9905g和985都流片了10万片12寸wafer,Kirin9905g可以制造大约4067万片,kirin990E可以在这基础之上在多出来16万片。而kirin985可以制造6378万片,kirin820可以在这基础上多出来11万片,而kirin820E可以再多出来9万片。
这个刀法,不行。相对于数千万片,多出来那么几万,实在是费拉不堪。所以我不如干脆再拟定几个阉割版,看看能拉多少产量。
这里可以想象,再kirin990E和985中间,性能的空挡还是有点大。这里干脆弄一个MP12的GPU,顺便阉割掉一半的内存通道,和985保持一致。既然Kirin820E都阉割了两个CPU核了,那Kirin990E也可以继续这么阉割,砍掉一个大核一个A55核。管这个叫Kirin990EE。甚至,还可以依赖7nmEUV的电气性能优势,这990还可以继续砍到MP10,然后超点频。至于这俩的命名,986和987都行。最后一位,当然不能大于7,因为众所周知,996的6指的事一周的工作天数,而一周不会大于7天,所以最后一位当然不能大于7。
那么经过这么大刀阔斧的阉割,Kirin990EE相对990E,提升了1.41%的良品率,而这个990EEE在这基础之上又提升了0.33%的良品率。换成片数,K990EE又增加了71万片,K990EEE又能再多出来接近17万片。那这把阉割,可比990E带劲多了。
这里还可以想象,可以将kirin820E和上面的假设的kirin990EEE继续阉割,也可以让他去替换kirin810的定位。这里带上kirin990EEE继续阉割的合理性,也会下面有解释。
这里可以在kirin820E的基础上继续阉割到MP5甚至MP4,屏蔽NPU大核而使用tiny核。不管怎么样反正命名815得了。
经历了神奇阉割的MP5版本姑且就叫Kirin820EE和MP4版本的820EEE,前者的良品率能提升0.25%,后者在前者基础上还能提升0.09%。即使是有更大的基数的上,前者只能再多出来17万片,后者在前者基础上多出来接近6万片。
相比之下我们可以脑补一个MP6的Kirin990EEEE,甚至再砍掉NPU大核的990EEEEE。990EEEE可以提升良品率0.67%,990EEEEE可以在990EEEE的基础上再提升0.32%的良品率,也就分别再多拿出来接近34万片和16万片。至于命名就975,815+,816,817都可以。
当然,因为实际机型的原因,建议直接一步到位,阉割到只保留Kirin990EEE/990EEEEE/820EEE这三个SKU。
| TOTAL | WORKING | yield | A76 cluster big | A76 cluster mid | A55 Cluster | GPU Core | NPU big | NPU little | DDR channel | ||||
| K990 | 508 | 406.7221 | 80.06% | 2 | 2 | 4 | 16 | 2 | 1 | 4 | |||
| K990E | 508 | 408.3553 | 80.38% | 2 | 2 | 4 | 14 | 2 | 1 | 4 | |||
| K990EE | 508 | 415.4993 | 81.79% | 1 | 2 | 3 | 12 | 1 | 1 | 2 | |||
| K990EEE | 508 | 417.1742 | 82.12% | 1 | 2 | 3 | 10 | 1 | 1 | 2 | |||
| K900EEEE | 508 | 420.5478 | 82.79% | 1 | 2 | 3 | 6 | 1 | 1 | 2 | |||
| K990EEEEE | 508 | 422.1785 | 83.11% | 1 | 2 | 3 | 6 | 0 | 1 | 2 | |||
| K985 | 688 | 637.8668 | 92.71% | 1 | 3 | 4 | 8 | 1 | 1 | 2 | |||
| K820 | 688 | 639.0130 | 92.88% | 1 | 3 | 4 | 6 | 1 | 0 | 2 | |||
| K820E | 688 | 639.9398 | 93.01% | 0 | 3 | 3 | 6 | 1 | 0 | 2 | |||
| K820EE | 688 | 641.6570 | 93.26% | 0 | 3 | 3 | 5 | 0 | 1 | 2 | |||
| K820EEE | 688 | 642.2336 | 93.35% | 0 | 3 | 3 | 4 | 0 | 1 | 2 |
| K990 | 40672207 | |
| K990E | 40835529 | 163322 |
| K990EE | 41549930 | 714400 |
| K990EEE | 41717417 | 167488 |
| K900EEEE | 42054780 | 337363 |
| K990EEEEE | 42217848 | 163068 |
| K985 | 63786682 | |
| K820 | 63901302 | 114621 |
| K820E | 63993976 | 92674 |
| K820EE | 64165701 | 171725 |
| K820EEE | 64223355 | 57654 |
| 芯片量 | 增加量 |
这里就不开玩笑了,为什么我在这里死命阉割,都不能增加多少可用片数。简单来说,就是屏蔽本身事因为,当你屏蔽了这些部分,实际上就良品率上说,就几乎等同于一个面积更小的芯片。但是不变的是,无论你屏蔽多少面积,一片wafer上都不能切割出来更多芯片,也就是说无论怎么阉割,终究只是在毕竟一个明确的上限。那就是一片wafer上能切割下来的片数。
在这里我们可以假设,有两个缺陷密度和前文提到的一样的工艺,还有一个缺陷密度在0.5defects/cm^2的工艺,这也算是一个工艺能大量生产大约算界限。在这些工艺上生产100mm^2的正方形芯片,并且在这基础上屏蔽一定面积,计算能在一片12寸wafer上可用的片数。并且相对应的,对比原生就这个面积芯片的片数。

这个数轴可能对屏蔽的数据不太友好,再换成对数轴。

这里可以看到,越成熟的工艺,屏蔽的提升空间越小。简单来说就是因为缺陷密度更低,所以他更容易实现高良品率,也更加逼近极限,所以显得提升空间小。
而原生制造一个更小的die,可以明显的和屏蔽拉开产量上的差距,这种产量上的差距,就会直接反映为成本更低。看图像上,屏蔽了10%以上的面积,差距就会很大了。而屏蔽到了35%的面积,成本就几乎差距了一倍。
当然实际上这么多SKU,每一个都单独的流片,那成本也会很高。所以一般大部分厂商总会做一点屏蔽的SKU填补市场定位的空间。另外一方面,很多手机芯片厂商干脆就是拿老的芯片拉下定位来填补市场定位,通过这种方式,每一年只需要更新定位相对偏高的和旗舰两个芯片,就足够填满市场定位了。在今天,还在每一代生产很多不同配置的芯片而不是大批量的屏蔽来填补市场的也就Intel和NVIDIA这两个厂商了。两者因为目前还没有推出和AMD的一样MCM产品,所以依旧需要推出一个比较多的配置的芯片才能填补定位。不过Intel在Tigerlake上,U作为一个4核的die和H顶配8核,实际上笔记本标压定位上,只要推把之前的TGL-U的die拿出来填4核标压定位,8核填以上定位,也算是研发压力在控制了。

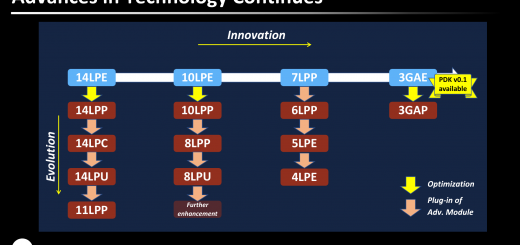
好家伙,intel不断在14nm+++..,你搁这不挺EEE..
好家伙,intel不断在14nm+++..,你搁这不断EEE..
好家伙,intel不断+++..,你搁这不断EEE..