Cortex-X3/A715:安卓设备的现状
ARM于很久之前就发布了新的X3/A715内核,
1.1 新的分支预测结构:多级/解耦
在通常的情况中,时序和容量(capacity)是不可兼得的,如果你需要更大的容量通常需要以更长的延迟作为代价。于是无论是CPU缓存还是别的,总体上都有更多分级的趋势,更多级更连续的容量和时延变化可以很好的优化性能。
在X3中,其中最明显的就是分支预测器的3级BTB设计。曾经这样的设计在A76中出现过,但是在之后的架构中马上就遭到了抛弃。
同样的,X3拥有X2开始的与预取解耦的分支预测器,不同部分之间通过队列(queue)缓冲,提高分支预测器的吞吐和减少bubble。


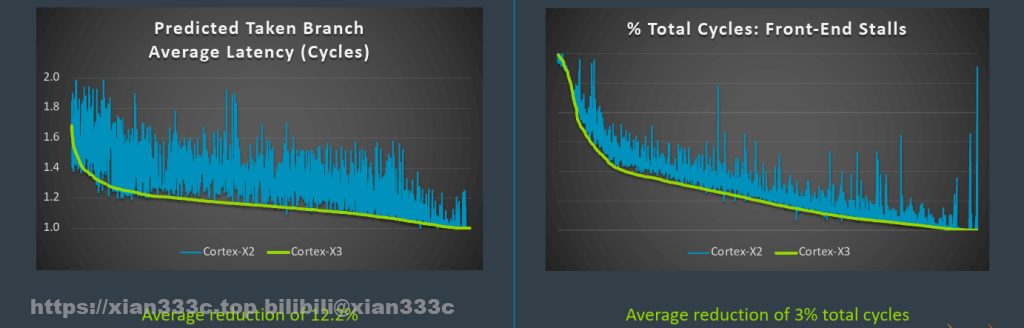
此外还增加了一个专用于间接分支(indirect branches)的预测器。就结果上来说,X3的分支预测消耗的周期数降低了12.2%,前端停滞(Front End Stall)的周期数减少了3%。分支误预测减少了6.1%。

1.2 吞吐和内存子系统
接下来的部分要相对无聊些。
1.2.1前端(Front End)
前端中,X3从X2的5解码宽度增加到6,相对的是MOPs Cache从3K缩小到了1.5K,但是给MOPs预取减少了一个CPU周期。

1.2.2 Mid Core/Reorder&Execution
乱序发射窗口增加到340(X2为288),增加了两个简单的ALU(ADD/SHIFT/…)

| X2 | X3 | ||
| RoB | 288 | 320 | 11% |
| Mops Cache | 3072 | 1536 | -50% |
| Mispredict pipeline stage | 10 | 9 | -10% |
| decoder | 5 | 6 | 20% |
| Simple ALU | 4 | 6 | 50% |
| MUL ALU | 2 | 2 | 0% |
| DIV ALU | 1 | 1 | 0% |
1.2.3内存子系统(memory subsystem)
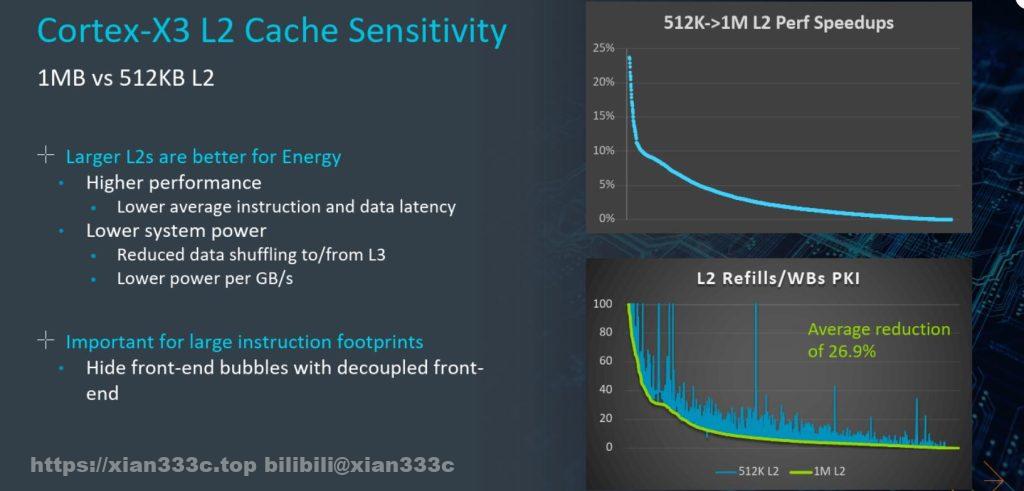
整数load带宽从24B/C增加到32B/C,以及一个并没有特别明确的OoO windows/structure提升25%。还有两个新增的数据预取引擎(data prefetch engine)掩盖延迟。

ARM还对比了X3选配1MiB或者0.5MiB的二级缓存的情况,二缓refill/写回(write back)的减少了26.9%
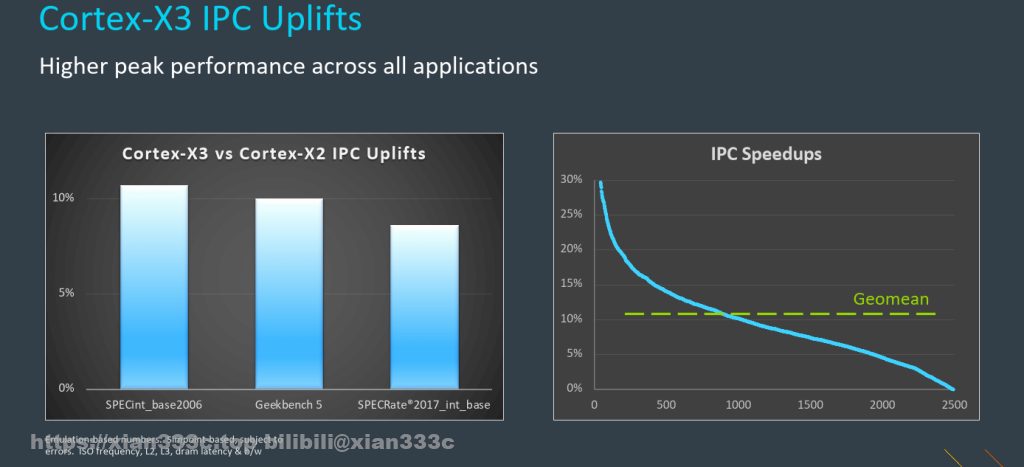
1.2.4 X3的IPC
ARM估记时钟指令吞吐量提高11%(取决于不同项目)
2.1 A715:改进分支预测器,取消支持Arch32
A715使用了基本于X3相同的分支预测器,同样拥有三级的BTB,但具体配置未知。分支预测器支持每周期吞吐两个条件分支(condition branch)
由于A715取消了arch32支持,decoder的大小减小到了A710的1/4。decoder宽度从4增加到了5,与X3相同,从1.5K的Mops Cache取消了Mops Cache。
内存系统上,增加了load replay queue的大小(但是具体未知),两倍了data cache banks提高带宽,增加了50%的L2 TLB。
| A710 | A715 | ||
| decoder | 4 | 5 | 25% |
| Mop Cache | 1536 | 0 | -100% |
| RoB | 160 | 192? | |
| L2 TLB | 1024 | 1536 | 50% |
| Simple ALU | 4 | 4 | 0% |
| MUL ALU | 1 | 1 | 0% |
| DIV ALU | 1 | 1 | 0% |
A715并没有提及时钟性能提升,只有同功率下提升5%的性能
3. SPEC06 INT性能功耗


从ARM的演示看,X3的功耗上限虽然会提高,但是其实能耗比并没有什么变化。某种角度上可以说是可靠的提升,而相比之下A715的功耗限制倒是可以认为是延续了传统的A系列的功耗。
和苹果相比X3仍然属于介于A13和A14之间,X2则更接近于A13。
4.1 这个性能真的有那么有用吗?Web性能的不对应
前面说了X3已经在A13和A14之间了,可是现实是真的是这样吗?
我在这里要谈论的是web性能(JS性能),虽然这种可以在浏览器就完成的测试好像并不专业,但是你需要注意的是,在现实的使用场景中,web应用是很常见的。
从你使用的阿里系应用到随处可见的小程序再到你想有多少app都可以直接在在里面塞个浏览器从里面打开网页。甚至你真的能在chrome里面打开阿里系app内的东西。
不仅如次,几乎所有日常使用的场景都是强时序的,这意味着绝大部分使用情况下,你只需要一个足够强大的线程,而web更不是例外。

Web测试可以分为简单两种,一种是一系列性能测试脚本的集合,另一种是比较标准化的web使用场景测试。两种测试的性能需求也是不同的。

可以看到,因为Kraken 1.1和Octane V2本身并不大,这些测试都是非常顺畅的并没有太多的各方面的瓶颈,CPU资源的50-60%都得到了利用。而Speedometer 2.0/2.1和Basemark Web 3.0 CPU都不仅仅依赖内存,而且非常甚至极端的依赖CPU前端,最终只有14-33%的CPU资源得到了利用。GeekBench5的运行比较顺畅,对前端依赖也更少。SPEC虽然依赖内存,更依赖分支预测,但是对CPU前端的依赖程度在图表中也只能说是一般。

这时候可以发现,主要的性能瓶颈除了内存子系统和分支预测以外主要出现在指令缓存未命中和指令TLB未命中。这样不如来看看ARM平台的相关配置的情况以及能够发挥的性能的性能:
| A11 | A12/A13 | A14/A15 | A76/A77 | A78/A710/A715 | X1/X2/X3 | |
| L1 I | 64KiB | 128KiB | ≥192KiB | 64KiB | 32/64KiB | 64KiB |
| I TLB | ? | ? | ? | 48entry | 48entry | 48entry |



可以看到,Web性能和Geekbench 5之类的跑分并不是对应的。在一个比较理想的评价系统中,你应该认为你跑到多少成绩就能够得到相对应的性能。这意味着当你将跑分和另一种使用的性能两者画成图像,应当是这一个狭窄的直线。
在这里只有瓶颈最小的Octane V2做到了类似的事,所有芯片的成绩构成了比较集中的类似一条直线。而kraken 1.1种中这意味着,即使ARM的CPU和苹果的A系列大核拥有相同的Geekbench5成绩的情况下,苹果的A系列此时还要比ARM CPU高了至少40%的Web性能。而在speedometer 2.0/2.1中,从长期来看,ARM还需要在各方面做一系列改进才能接近苹果的A系列大核,相对的X86平台整体在Web性能中都出现了明显的在相同Geekbench 5成绩时会显著的落后于苹果A系列的情况。(尤其是M2在chrome中已经甩开了其他对手,在safari中已经快了对手几乎数代CPU的差距)

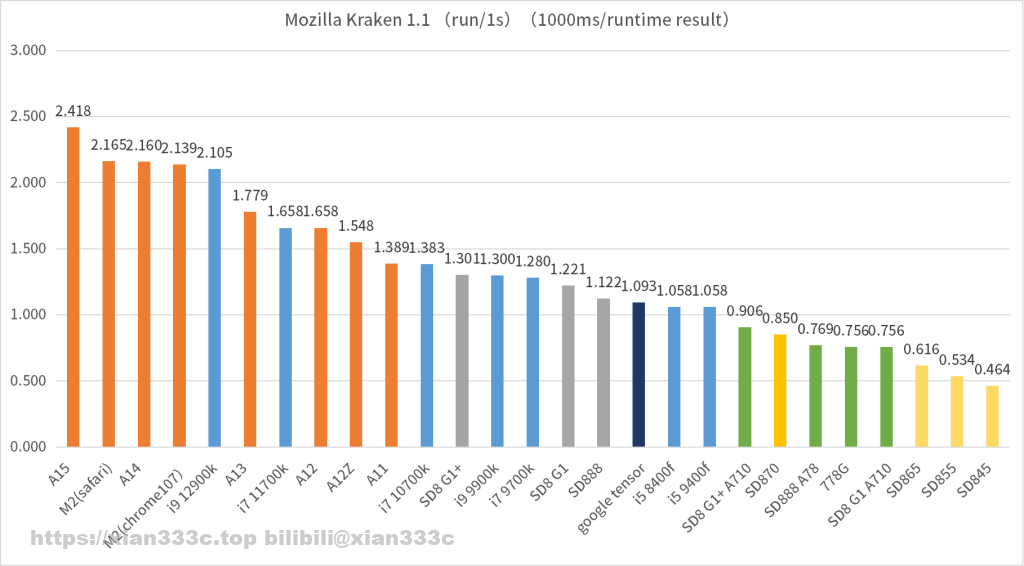
就最终的性能上X2的8Gen1+在是Speedometter 2.0中还处于与A12/A12Z相同的水平,而在kraken1.1中甚至还到不了A11的水平。另外一点是,在所有Web应用中A78开始的中核都拥有与A77旗舰CPU类似或者更高的性能。在这一里可以看到进入X1/A78世代时,ARM的web的时钟性能中的提升:


X1一代带来了大约60%的web时钟性能的提升,即使是A78都有30-40%的时钟性能提升,但是在这之后X2/A710的提升非常的有限。而在这一代X3和A715实际的提升幅度我觉得还是只能进行观望。
4.2 调度发挥
你还需要注意的是,即使ARM的CPU平台在A78/X1一代得到了巨大的提升,但是现实情况是你可能完全用不到这样的性能。SD888开始的软件调度以及X2抛弃了Arch32的支持之后,32位app更加无法使用到大核的性能。我记得印象很深的是,某个中国厂商的手机在使用chrome也会默认使用中核运行,加上大部分中国大陆地区的浏览器app还仅拥有arch32的lib,最后才找一个冷门的还拥有64位lib的这一个chromium浏览器app才真正发挥出了性能。


当你用notebook check查看大量样本的时候会发现,有相当部分的设备都会至少降频大核运行,乃至运行在中核上。甚至有不少设备只能够得到理想情况的70%乃至50%的性能发挥。如果你还用实际这么多设备的平均水平,这才会是更加真实的性能水平:


实际上大量设备的平均性能是,SD8G1和Google Tensor一个水平,而SD8G1/G1+和google tensor还在介于A12和A11中间。至于SD888等等则距离APPLE A11还有些差距,也难怪现在这些手机在平时的应用打开之类的还和pixel4之类的设备拉不开特别明显的差距。
可以说安卓设备和ARM设备,最大的可能的问题是一方面ARM CPU可能在日常涉及到的web app情况和苹果的的巨大差距,同时调度上的问题使得现在的设备更加和过去的设备也拉不开差距。即使X3能够达到巨大的提升,在日常使用的调度问题不解决下,也很难得到明显的可感知的提升。
- 更新了Intel和SD855的speedometer数据,消除chrome版本的影响。
- 更新了一个speedometer 2.0 actual performance的另一个图表。


啥时候可以讲一下d8100、8200这两个呢
大大,讲讲Adreno740 730和苹果吧