D1200和SD888:功耗和缓存,预测模型。
再SD888的内容中提到了,按器X1和A78核心的功耗高,是可以建立一个模型完成的。即A78和X1的整数和访存后端是完全相同的,所以其功耗和性能本身就是后端利用率的差距造成的。
某种意义上,这种差距就是CPU利用率的差距。相关的概念实际上在之前是有讨论的。
这里已知两个CPU,其仅仅有缓存配置有区别。CPU1和2的性能用已知,并且只知道CPU1的功耗,那么就可以建立通过这么一个方式估算CPU2的功耗

这个方式已经在SD888中得到了验证。不如说下面的内容是在其他平台对类似的情况进行验证。
D1200的验证
实际上,我在最初撰写D1200的部分中,并未使用这个模型进行预测,实际上在撰写过程中,我就对D1100的功耗有些震惊。
这是建立一个模型的基础,无论如何,一个模型需要在现实的情况下进行修正,去符合现实情况。在撰写的过程中,实际上我必须以D1100作为另一个基准参考。而在实际上,D1200的结果与D1100大相径庭。所以这里我需要重新捡起来这个模型,对这个过程进行验证。
这里需要考虑的问题是,另外一个不确定的要素是TSMC的N6的具体表现,实际上一个节点的表现可以有很大差距,比如K9000实际上作为一个N5的节点,它体现的功耗降低幅度远逊于苹果A14。而无论A14还是K9000都仍然和TSMC的A72验证功耗有一定区别。
这里将节点功耗作为一个系数修正:

这里大约得到这个修正系数为0.8096,即1-0.8096=0.1904,这里 TSMC N6相对于SS N5降低了大约19.04%的功耗,实际上考虑到苹果(-2~4%)和海思(8%)相对于TSMC的k=0.8实际的偏差,可以认为是正常范围的。甚至按这里来说,海思的N5(k=0.88)还不如TSMC N6(k=0.8096)
增加完功耗节点的修正,可以看到,这里可以非常接近实际的情况,可以看到的是,D1200的A78中核和大核也显示出了这样的特征
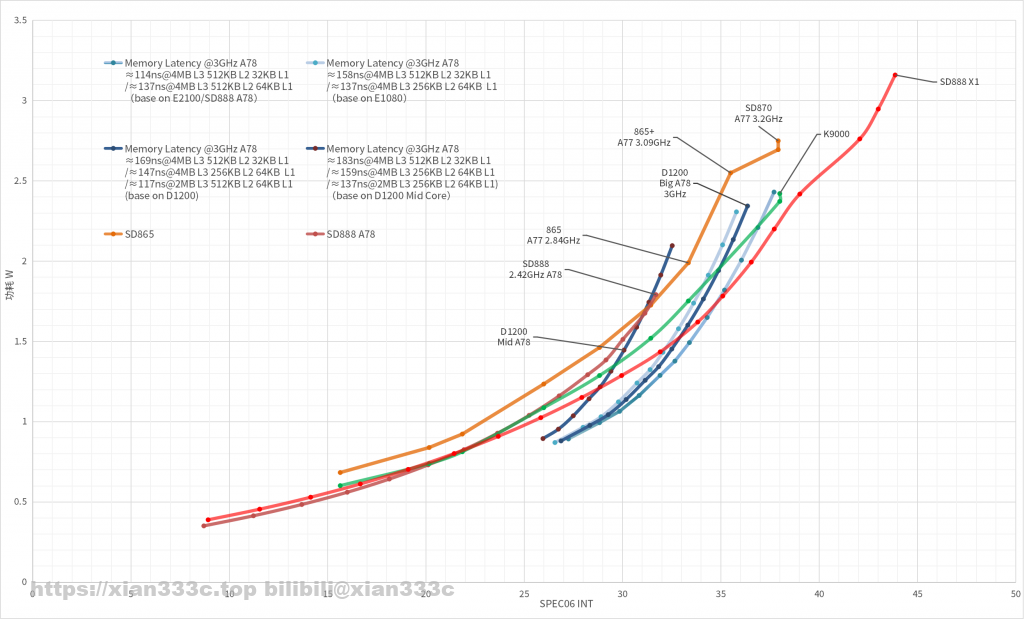
缓存、性能和功耗
既然在前面得到了一个节点的修正系数,利用这个系数就可以还原到相同工艺性能下不同缓存配置的性能能功耗曲线:
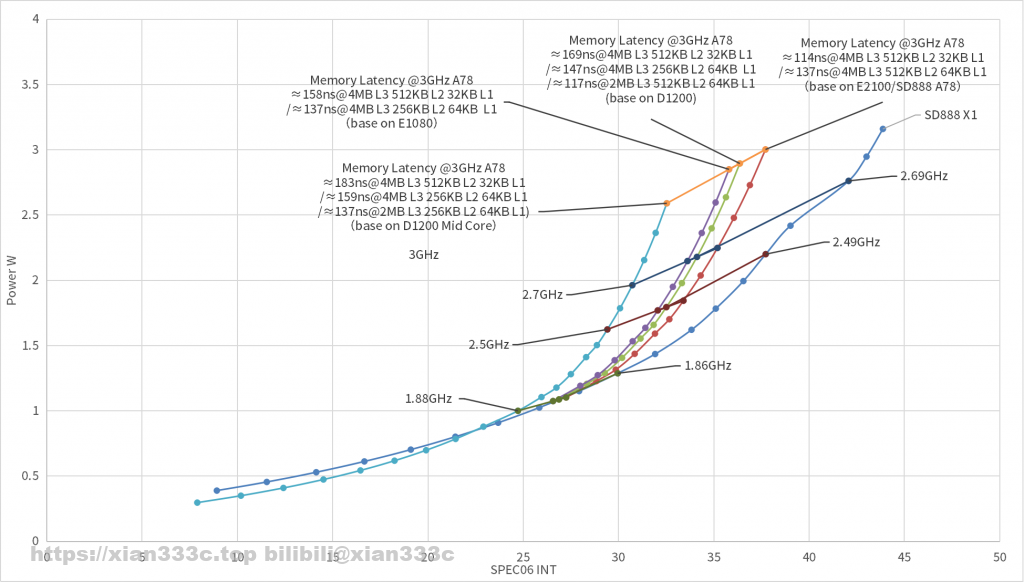
可以看到缓存配置的差距主要体现在高频部分上,随着频率增加这个差距就越明显。而在低频率低性能区间,实际上砍了缓存的配置的能耗比更高,功耗更低。
类似的现象也在之前提到的GPU上,而相对于之前预估的结果,砍缓存的结果自然也就更加能看了。虽然我画了这个最逊的砍缓存的结果,但是话说回来,实际上反正也没人指望这种高强度砍缓存的核心跑多高的频率。

滴,群友卡。大佬什么时候讲讲内存融合技术?